Capítulo 5 Importação de Dados via Pacotes
Uma das grandes vantagens de se utilizar o R é a quantidade de dados que podem ser importados através da internet. Isso é especialmente prático pois uma base de dados pode ser atualizada através de um simples comando, evitando o tedioso trabalho de coleta manual. Ao usarmos pacotes para importar dados, esta etapa da pesquisa se torna reproduzível e mais rápida, facilitando o compartilhamento e futura execução do nosso código.
Neste capítulo vou descrever e dar exemplos de importação de dados para os mais importantes e estáveis pacotes especializados na importação de para dados financeiros e econômicos no Brasil e exterior. A lista inclui:
-
GetQuandlData(M. S. Perlin 2019) - Importa dados econômicos e financeiros do vasto repositório de dados da plataforma Quandl.
-
BatchGetSymbols(M. Perlin 2022a) - Importa dados de preços diários de ações e índices do Yahoo Finance.
-
GetTDData(M. Perlin 2022c) - Importa dados de títulos de dívida pública do Brasil diretamente do site do Tesouro Direto.
-
GetBCBData(M. Perlin 2022b) - Importa dados do grande repositório de séries temporais do Banco Central do Brasil, local obrigatório para qualquer economista que trabalha com dados.
-
GetDFPData2(M. Perlin and Kirch 2022a) - Importa dados do sistema DFP – Demonstrativos Financeiros Padronizados – de empresas negociadas na B3, a bolsa Brasileira. O repositório inclui documentos financeiros tal como o balanço patrimonial, demonstrativos de resultados, entre vários outros.
-
GetFREData(M. Perlin and Kirch 2022b) - Importa dados do sistema FRE – Formulário de Referência – da bolsa Brasileira. Esta inclui diversos eventos e informações corporativas tal como composição do conselho e diretoria, remuneração dos conselheiros, entre outras.
5.1 Pacote GetQuandlData
Quandl é um repositório de dados abrangente, fornecendo acesso a uma série de tabelas gratuitas e pagas disponibilizadas por diversas instituições de pesquisa. Como ponto inicial, recomendo fortemente que você navegue nas tabelas disponíveis no site da Quandl18. Verás que uma grande proporção dos repositórios de dados abertos em economia e finanças também estão disponíveis no Quandl.
Pacote Quandl (Raymond McTaggart, Gergely Daroczi, and Clement Leung 2021) é a extensão oficial oferecida pela empresa e disponível no CRAN. No entanto, o pacote tem alguns problemas quanto a estrutura de dados de saída19 e, para resolver, escrevi o meu próprio pacote GetQuandlData (M. S. Perlin 2019). O diferencial de GetQuandlData é a saída de dados já estruturados, prontos para uma posterior análise.
A primeira e obrigatória etapa no uso de GetQuandlData é registrar o usuário no site. Logo em seguida, vá para Account Settings e procure pela seção You API Key. Este local deve mostrar uma senha, tal como Asv8Ac7zuZzJSCGxynfG. Copie o texto para a área de transferência (control + c) e, no R, defina um objeto de contendo o conteúdo copiado da seguinte maneira:
# set FAKE api key to quandl
my_api_key <- 'Asv8Ac7zuZzJSCGxynfG'Essa chave API é exclusiva para cada usuário e a apresentada aqui não funcionará no seu computador. Você precisará obter sua própria chave de API para executar os exemplos do livro. Depois de encontrar e definir sua chave, vá para o site do Quandl e use a caixa de pesquisa para procurar o símbolo da série temporal de interesse.
Como exemplo, usaremos dados do preço do ouro no mercado Londrino. O código para esta série no Quandl é 'LBMA/GOLD'. Observe que a estrutura de um identificador de tabelas no Quandl é sempre a mesma, com o nome do banco de dados primeiro e o nome da tabela depois, separados por uma barra (/).
Agora, com a chave API e o identificador da tabela, usamos a função get_Quandl_series para baixar os dados de 1980-01-01 a 2021-01-01:
library(GetQuandlData)
library(tidyverse)
# set symbol and dates
my_symbol <- c('GOLD' = 'LBMA/GOLD')
first_date <- '1980-01-01'
last_date <- '2021-01-01'
# get data!
df_quandl <- get_Quandl_series(id_in = my_symbol,
api_key = my_api_key,
first_date = first_date,
last_date = last_date)
# check it
glimpse(df_quandl)R> Rows: 10,763
R> Columns: 9
R> $ `USD (AM)` <chr> "1766.6", "1772.9", "1766.75", "1758.9…
R> $ `USD (PM)` <chr> "1761.25", "1779.75", "1772.4", "1753.…
R> $ `GBP (AM)` <chr> "1450.03", "1452.36", "1443.26", "1447…
R> $ `GBP (PM)` <chr> "1451.62", "1457.26", "1444.86", "1451…
R> $ `EURO (AM)` <chr> "1734.09", "1732.3", "1722.23", "1724.…
R> $ `EURO (PM)` <chr> "1735.54", "1743.62", "1727.91", "1725…
R> $ series_name <chr> "GOLD", "GOLD", "GOLD", "GOLD", "GOLD"…
R> $ ref_date <date> 2022-08-03, 2022-08-02, 2022-08-01, 2…
R> $ id_quandl <chr> "LBMA/GOLD", "LBMA/GOLD", "LBMA/GOLD",…Observe como definimos o nome da série temporal em linha id_in = c('GOLD' = 'LBMA/GOLD'). O nome do elemento – GOLD – se torna uma coluna chamada series_name no dataframe de saída. Se tivéssemos mais séries temporais, elas seriam empilhadas na mesma tabela.
Para verificar os dados, vamos criar um gráfico com os preços do ouro ao longo do tempo. Aqui, usaremos o pacote ggplot2 para criar a figura. Por enquanto você não precisa se preocupar com o código de criação de gráficos. Teremos o capítulo 10 inteiro dedicado ao tópico.
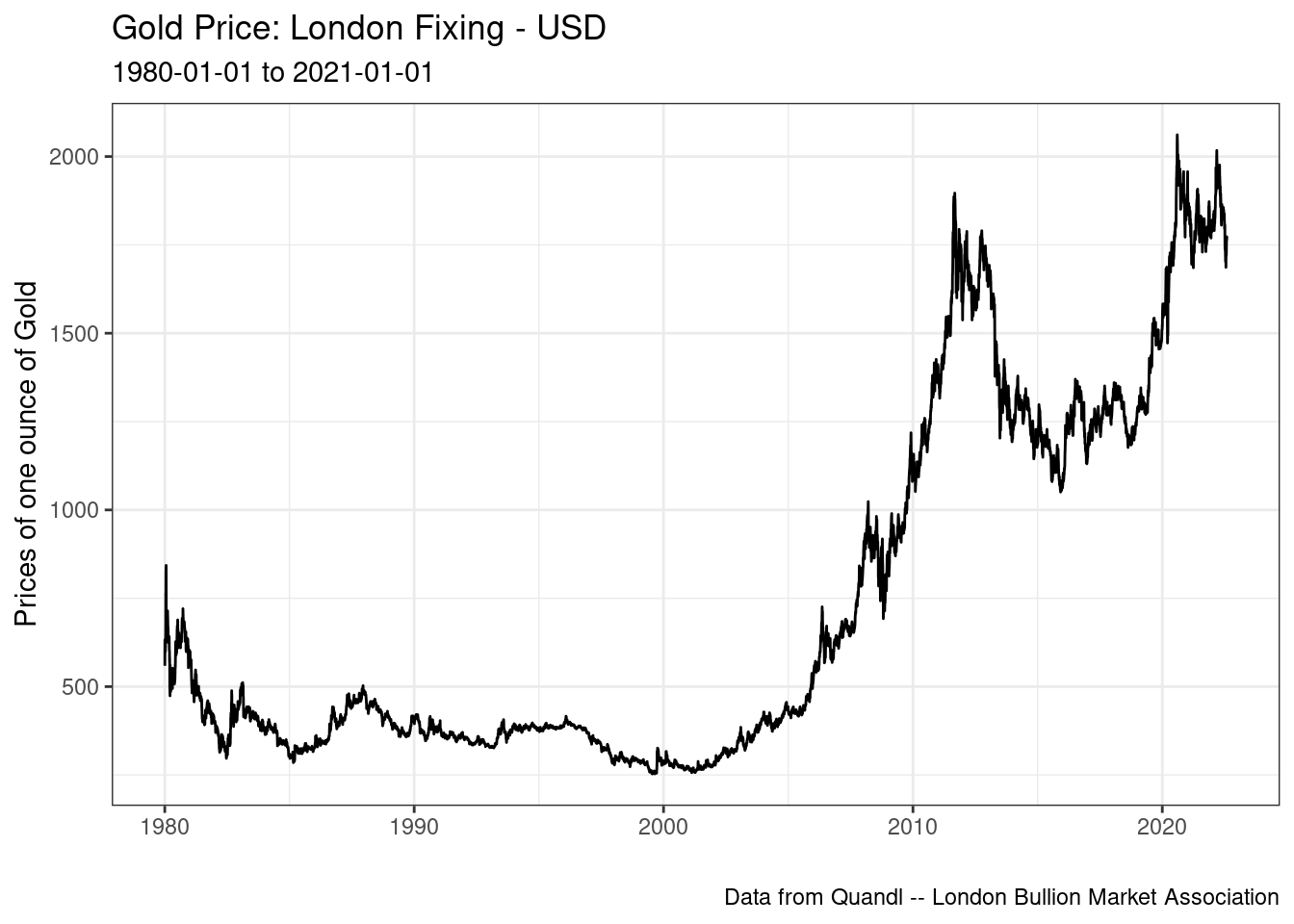
De modo geral, os preços do ouro permaneceram relativamente estáveis entre 1980 e 2000, atingindo um pico após 2010. Uma possível explicação é a maior demanda por ativos mais seguros, como o ouro, após a crise financeira de 2009. No entanto, o ouro nunca foi um investimento eficiente a longo prazo. Para mostrar isso, vamos calcular seu retorno anual composto de 1980-01-02 a 2022-08-03:
# sort the rows
df_quandl <- df_quandl %>%
mutate(USD = as.numeric(`USD (AM)`)) %>%
arrange(ref_date)
total_ret <- last(df_quandl$USD)/first(df_quandl$USD) - 1
total_years <- as.numeric(max(df_quandl$ref_date) -
min(df_quandl$ref_date) )/365
comp_ret_per_year <- (1 + total_ret)^(1/total_years) - 1
print(comp_ret_per_year)R> [1] 0.02737004Encontramos o resultado de que os preços do ouro em USD apresentam um retorno composto equivalente a 2,74% ao ano. Este não é um resultado de investimento impressionante de forma alguma. Como comparação, a inflação anual para os EUA no mesmo período é de 3,22% ao ano. Isso significa que, ao comprar ouro em 1980, o investidor recebeu menos que a inflação como retorno nominal, resultando em perda de poder de compra.
5.1.1 Importando Múltiplas Séries
Ao solicitar várias séries temporais do Quandl, pacote GetQuandlData empilha todos os dados em um único dataframe, tornando mais fácil trabalhar com as ferramentas do tidyverse. Como exemplo, vamos olhar para o banco de dados RATEINF, o qual contém séries temporais das taxas de inflação ao redor do mundo. Primeiro, precisamos ver quais são os conjuntos de dados disponíveis:
library(GetQuandlData)
library(tidyverse)
# databse to get info
db_id <- 'RATEINF'
# get info
df_db <- get_database_info(db_id, my_api_key)
glimpse(df_db)R> Rows: 26
R> Columns: 8
R> $ code <chr> "CPI_ARG", "CPI_AUS", "CPI_CAN", "CPI…
R> $ name <chr> "Consumer Price Index - Argentina", "…
R> $ description <chr> "Please visit <a href=http://www.rate…
R> $ refreshed_at <dttm> 2020-10-10 02:03:32, 2022-11-19 02:0…
R> $ from_date <date> 1988-01-31, 1948-09-30, 1989-01-31, …
R> $ to_date <date> 2013-12-31, 2022-09-30, 2022-10-31, …
R> $ quandl_code <chr> "RATEINF/CPI_ARG", "RATEINF/CPI_AUS",…
R> $ quandl_db <chr> "RATEINF", "RATEINF", "RATEINF", "RAT…Coluna name contém a descrição das tabelas com os seguintes nomes:
R> [1] "Consumer Price Index - Argentina"
R> [2] "Consumer Price Index - Australia"
R> [3] "Consumer Price Index - Canada"
R> [4] "Consumer Price Index - Switzerland"
R> [5] "Consumer Price Index - Germany"
R> [6] "Consumer Price Index - Euro Area"
R> [7] "Consumer Price Index - France"
R> [8] "Consumer Price Index - UK"
R> [9] "Consumer Price Index - Italy"
R> [10] "Consumer Price Index - Japan"
R> [11] "Consumer Price Index - New Zealand"
R> [12] "Consumer Price Index - Russia"
R> [13] "Consumer Price Index - USA"
R> [14] "Inflation YOY - Argentina"
R> [15] "Inflation YOY - Australia"
R> [16] "Inflation YOY - Canada"
R> [17] "Inflation YOY - Switzerland"
R> [18] "Inflation YOY - Germany"
R> [19] "Inflation YOY - Euro Area"
R> [20] "Inflation YOY - France"
R> [21] "Inflation YOY - UK"
R> [22] "Inflation YOY - Italy"
R> [23] "Inflation YOY - Japan"
R> [24] "Inflation YOY - New Zealand"
R> [25] "Inflation YOY - Russia"
R> [26] "Inflation YOY - USA"O que estamos buscando são as séries 'Inflation YOY - *', as quais contém a inflação ano-ao-ano (Year On Year – YOY) de diferentes países. Vamos agora filtrar o dataframe para manter apenas as séries de inflação anual para quatro países selecionados:
selected_series <- c('Inflation YOY - USA',
'Inflation YOY - Canada',
'Inflation YOY - Euro Area',
'Inflation YOY - Australia')
# filter selected countries
idx <- df_db$name %in% selected_series
df_db <- df_db[idx, ]Agora importamos as séries usando get_Quandl_series:
my_id <- df_db$quandl_code
names(my_id) <- df_db$name
first_date <- '2010-01-01'
last_date <- '2021-01-01'
df_inflation <- get_Quandl_series(id_in = my_id,
api_key = my_api_key,
first_date = first_date,
last_date = last_date)
glimpse(df_inflation)R> Rows: 500
R> Columns: 4
R> $ series_name <chr> "Inflation YOY - Australia", "Inflatio…
R> $ ref_date <date> 2022-06-30, 2022-03-31, 2021-12-31, 2…
R> $ value <dbl> 6.1, 5.1, 3.5, 3.0, 3.8, 1.1, 0.9, 0.7…
R> $ id_quandl <chr> "RATEINF/INFLATION_AUS", "RATEINF/INFL…Por fim, construimos um gráfico para vizualizar as séries de inflação:
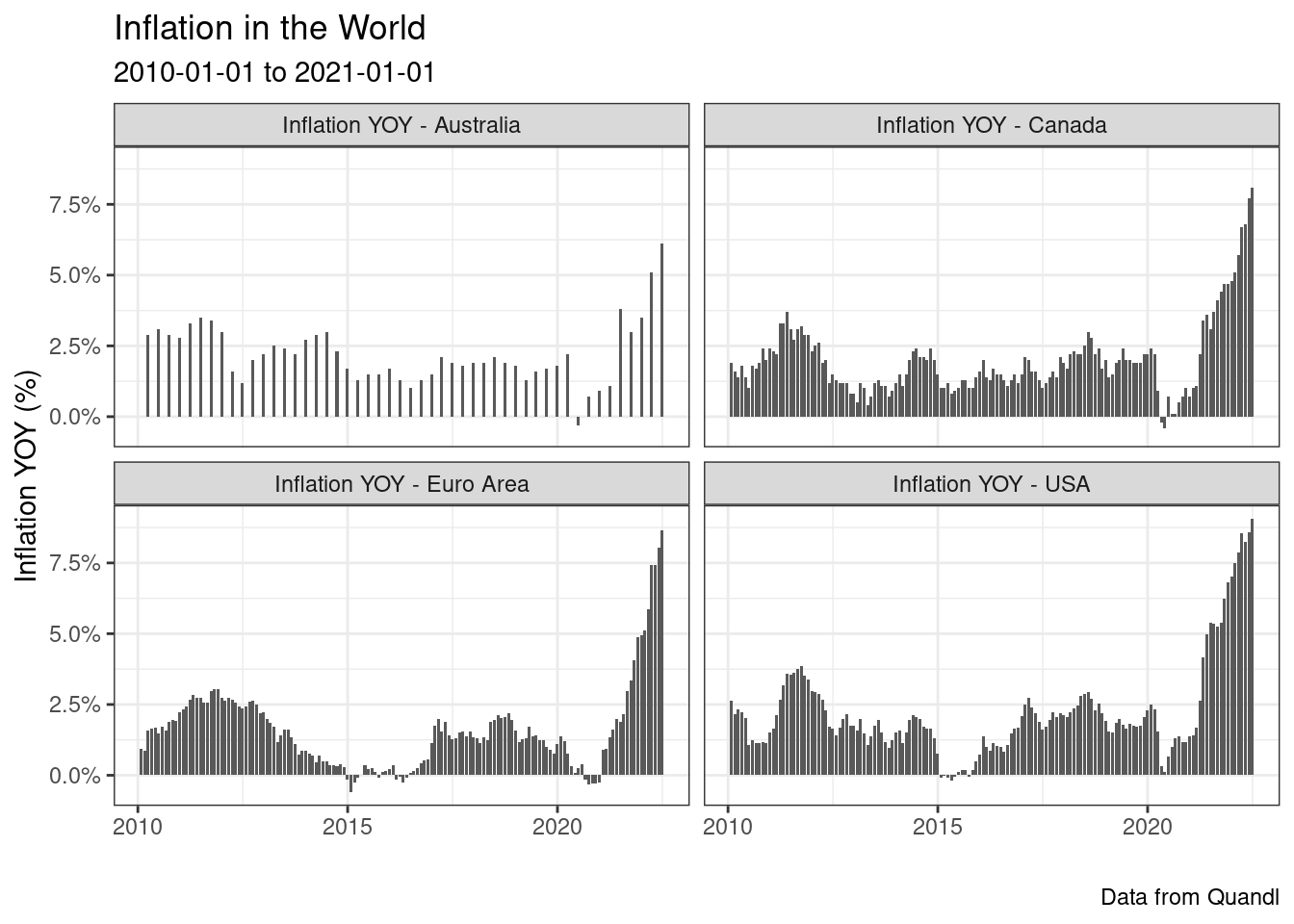
Como podemos ver, com algumas linhas de código do R conseguimos importar dados atualizados da inflação de diferentes regiões do mundo. O retorno de um dataframe no formato empilhado facilitou o processo de análise pois essa é a estrutura de dados que o ggplot2 espera.
5.2 Pacote BatchGetSymbols
Pacote BatchGetSymbols faz a comunicação do R com os dados financeiros disponíveis no Yahoo Finance. Essa gigantesca base de dados inclui valores agregados de preços e volumes negociados de ações na B3 e outras bolsas internacionais na frequência diária. Tudo que se precisa saber para acessar a base de dados são os identificadores das ações (tickers) e um período de tempo.
Os diferenciais do BatchGetSymbols são:
Limpeza e organização: todos os dados financeiros de diferentes tickers são mantidos no mesmo dataframe, facilitando a análise futura com as ferramentas do tidyverse.
Controle de erros de importação: todos erros de download são registrados na saída do programa. Caso uma ação em particular não exista no Yahoo Finance, esta será ignorada e apenas as demais disponíveis serão retornadas na saída do código;
Comparação de datas a um benchmark: os dados de ativos individuais são comparados com dados disponíveis para um ativo benchmark, geralmente um índice de mercado. Caso o número de datas faltantes seja maior que um determinado limite imposto pelo usuário, a ação é retirada do dataframe final.
Uso de sistema de cache: no momento de acesso aos dados, os mesmos são salvos localmente no computador do usuário e são persistentes para cada sessão. Caso o usuário requisitar os mesmos dados na mesma sessão do R, o sistema de cache será utilizado. Se os dados desejados não estão disponíveis no cache, a função irá comparar e baixar apenas as informações que faltam. Isso aumenta significativamente a velocidade de acesso aos dados, ao mesmo tempo em que minimiza o uso da conexão a Internet;
Desde versão 2.6 (2020-11-22) de BatchGetSymbols a pasta
default de cache do BatchGetSymbols se localiza no
diretório temporário da sessão do R. Assim, o cache é persistente apenas
para a sessão do usuário. Esta mudança foi motivada por quebras
estruturais nos dados do Yahoo Finance, onde os dados passados
registrados em cache não mais estavam corretos devido a eventos
coporativos. O usuário, porém, pode trocar a pasta de cache usando a
entrada cache.folder.
Acesso a tickers em índices de mercado: O pacote inclui funções para baixar a composição dos índices Ibovespa, SP500 e FTSE100. Isso facilita a importação de dados para uma grande quantidade de ações. Podes, por exemplo, baixar cotações de todas as ações que fazem parte de certo índice.
Processamento paralelo: Caso o usuário estiver baixando um grande volume de dados do Yahoo Finance, uma opção para execução paralela está disponível. Isto é, ao invés de usar apenas um núcleo na requisição dos dados, usamos vários ao mesmo tempo. O efeito prático é, dependendo do número de núcleos do computador, uma diminuição significativa no tempo total de importação.
Flexibilidade de formato: O pacote também oferece funções para modificar o formato dos dados. Caso o usuário deseje uma saída do dataframe no formato largo, onde tickers são colunas e as linhas os preços/retornos, basta chamar função BatchGetSymbols::reshape.wide. Da mesma forma, uma transformação temporal também é possível. Se o usuário desejar dados na frequência semanal, mensal ou anual, basta indicar na entrada freq.data da função.
Como exemplo de uso, vamos baixar dados financeiros referentes a quatro ações no último ano (360 dias) usando a função de mesmo nome do pacote. Os tickers de cada ação podem ser encontrados nos próprios sites do Yahoo Finance. Note que adicionamos texto .SA a cada um deles. Essa é uma notação específica do site e vale para qualquer ação Brasileira.
Na chamada da função BatchGetSymbols, utilizamos um valor de 0.95 (95%) para o input thresh.bad.data e '^BVSP' para bench.ticker. Isso faz com que a função compare as datas obtidas para cada ativo em relação ao nosso benchmark, o índice Ibovespa, cujo ticker no Yahoo Finance é ^BVSP. Se, durante o processo de importação, uma ação individual não apresenta mais de 95% de casos válidos em relação ao benchmark, esta é retirada da saída.
library(BatchGetSymbols)
library(dplyr)
# set tickers
my_tickers <- c('PETR4.SA', 'CIEL3.SA',
'GGBR4.SA', 'GOAU4.SA')
# set dates and other inputs
first_date <- Sys.Date()-360
last_date <- Sys.Date()
thresh_bad_data <- 0.95 # sets percent threshold for bad data
bench_ticker <- '^BVSP' # set benchmark as ibovespa
l_out <- BatchGetSymbols(tickers = my_tickers,
first.date = first_date,
last.date = last_date,
bench.ticker = bench_ticker,
thresh.bad.data = thresh_bad_data)A saída de BatchGetSymbols é um objeto do tipo lista, ainda não visto no livro. Por enquanto, tudo que precisas saber é que uma lista é um objeto flexível, acomodando outros objetos em sua composição. O acesso a cada elemento de uma lista pode ser feito pelo operador $. No capítulo 6 iremos estudar melhor esta classe de objetos.
Note que as entradas da função
BatchGetSymbols::BatchGetSymbols usam o “.” em seus nomes,
tal como thresh.bad.data, e bench.ticker,
enquanto o livro está escrito usando o traço baixo (_), tal
como thresh_bad_data, e bench_ticker. Esta
diferença pode resultar em problemas se, na falta de atenção, o usuário
trocar um pelo outro. Como regra, procure dar prioridade para o uso de
traço baixo nos nomes de objetos. Infelizmente algumas funções escritas
no passado acabaram ficando com a estrutura antiga e, para não
prejudicar os usuários, os nomes das entradas foram mantidos.
Voltando ao nosso exemplo, função BatchGetSymbols retorna uma lista com dois elementos: um dataframe com o resultado do processo de importação – df_control – e outro dataframe com os dados das ações – df_tickers. Vamos checar o conteúdo do primeiro dataframe.
# print result of download process
print(l_out$df.control)R> # A tibble: 4 × 6
R> ticker src download.status total.obs perc.be…¹ thres…²
R> <chr> <chr> <chr> <int> <dbl> <chr>
R> 1 PETR4.SA yahoo OK 246 1 KEEP
R> 2 CIEL3.SA yahoo OK 246 1 KEEP
R> 3 GGBR4.SA yahoo OK 246 1 KEEP
R> 4 GOAU4.SA yahoo OK 246 1 KEEP
R> # … with abbreviated variable names ¹perc.benchmark.dates,
R> # ²threshold.decisionObjeto df.control mostra que todos tickers foram válidos, com um total de 246 observações para cada ativo. Note que as datas batem 100% com o Ibovespa (coluna perc.benchmark.dates).
Quanto aos dados financeiros, esses estão contidos em l_out$df.tickers:
# print df_tickers
glimpse(l_out$df.tickers)R> Rows: 984
R> Columns: 10
R> $ price.open <dbl> 29.36, 29.30, 29.84, 26.99, 28…
R> $ price.high <dbl> 29.82, 29.64, 30.67, 28.49, 28…
R> $ price.low <dbl> 28.81, 28.86, 29.48, 26.20, 28…
R> $ price.close <dbl> 29.47, 29.43, 29.60, 28.36, 28…
R> $ volume <dbl> 84672200, 129384600, 135078600…
R> $ price.adjusted <dbl> 15.33113, 15.31032, 15.39875, …
R> $ ref.date <date> 2021-11-29, 2021-11-30, 2021-…
R> $ ticker <chr> "PETR4.SA", "PETR4.SA", "PETR4…
R> $ ret.adjusted.prices <dbl> NA, -0.0013573042, 0.005776432…
R> $ ret.closing.prices <dbl> NA, -0.0013572786, 0.005776418…Como esperado, a informação sobre preços, retornos e volumes está lá, com as devidas classes de colunas: dbl (double) para valores numéricos e date para as datas. Observe que uma coluna chamada ticker também está incluída. Essa indica em que linhas da tabela os dados de uma ação começam e terminam. Mais tarde, no capítulo 9, usaremos essa coluna para fazer diversos cálculos para cada ação.
5.2.1 Baixando Dados da Composição do Ibovespa
Outra função útil do pacote é BatchGetSymbols::GetIbovStocks, a qual importa a composição atual do índice Ibovespa diretamente do site da B3. Esse índice é um termômetro do mercado local e as ações que o compõem são selecionadas devido sua alta negociabilidade. Portanto, sequenciando o uso de GetIbovStocks e BatchGetSymbols, podemos facilmente baixar uma volumosa quantidade de dados de ações para o mercado Brasileiro. Considere o seguinte fragmento de código, onde realizamos essa operação:
library(BatchGetSymbols)
# set tickers
df_ibov <- GetIbovStocks()
my_tickers <- paste0(df_ibov$tickers,'.SA')
# set dates and other inputs
first_date <- Sys.Date()-30
last_date <- Sys.Date()
thresh_bad_data <- 0.95 # sets percent threshold for bad data
bench_ticker <- '^BVSP' # set benchmark as ibovespa
cache_folder <- 'data/BGS_Cache' # set folder for cache
l_out <- BatchGetSymbols(tickers = my_tickers,
first.date = first_date,
last.date = last_date,
bench.ticker = bench_ticker,
thresh.bad.data = thresh_bad_data,
cache.folder = cache_folder)Note que utilizamos a função paste0 para adicionar o texto '.SA' para cada ticker em df_ibov$tickers. A saída do código anterior não foi mostrada para não encher páginas e páginas com as mensagens do processamento. Destaco que, caso necessário, poderíamos facilmente exportar os dados em l_out para um arquivo .rds e futuramente carregá-los localmente para realizar algum tipo de análise.
Saiba que os preços do Yahoo Finance não são ajustados a dividendos. O ajuste realizado pelo sistema é apenas para desdobramentos das ações. Isso significa que, ao olhar séries de preços em um longo período, existe um viés de retorno para baixo. Ao comparar com outro software que faça o ajustamento dos preços por dividendos, verás uma grande diferença na rentabilidade total das ações. Como regra, em uma pesquisa formal, evite usar dados de ações individuais no Yahoo Finance para períodos longos. A excessão é para índices financeiros, tal como o Ibovespa, onde os dados do Yahoo Finance são bastante confiáveis uma vez que índices não sofrem os mesmos ajustamentos que ações individuais.
5.3 Pacote GetTDData
Arquivos com informações sobre preços e retornos de títulos emitidos pelo governo brasileiro podem ser baixados manualmente no site do Tesouro Nacional. O tesouro direto é um tipo especial de mercado onde pessoa física pode comprar e vender dívida pública. Os contratos de dívida vendidos na plataforma são bastante populares devido a atratividade das taxas de retorno e a alta liquidez oferecida ao investidor comum.
Pacote GetTDData importa os dados das planilhas em Excel do site do Tesouro Nacional e os organiza. O resultado é um dataframe com dados empilhados. Como exemplo, vamos baixar dados de um título prefixado do tipo LTN com vencimento em 2021-01-01. Esse é o tipo de contrato de dívida mais simples que o governo brasileiro emite, não pagando nenhum cupom20 durante sua validade e, na data de vencimento, retorna 1.000 R$ ao comprador. Para baixar os dados da internet, basta usar o código a seguir:
library(GetTDData)
asset_codes <- 'LTN' # Identifier of assets
maturity <- '010121' # Maturity date as string (ddmmyy)
# download
my_flag <- download.TD.data(asset.codes = asset_codes)
# read files
df_TD <- read.TD.files()Vamos checar o conteúdo do dataframe:
# check content
glimpse(df_TD)R> Rows: 24,733
R> Columns: 5
R> $ ref.date <date> 2002-03-18, 2002-03-19, 2002-03-20, 20…
R> $ yield.bid <dbl> 0.1977, 0.1975, 0.1967, 0.2005, 0.1983,…
R> $ price.bid <dbl> 720.96, 721.70, 723.09, 719.48, 722.38,…
R> $ asset.code <chr> "LTN 070104", "LTN 070104", "LTN 070104…
R> $ matur.date <date> 2004-01-07, 2004-01-07, 2004-01-07, 20…Temos informações sobre data de referência (ref.date), retorno contratado (yield.bid), preço do contrato na data (price.bid), nome do contrato (asset.code) e dia de maturidade (matur.date). No gráfico a seguir checamos os dados:
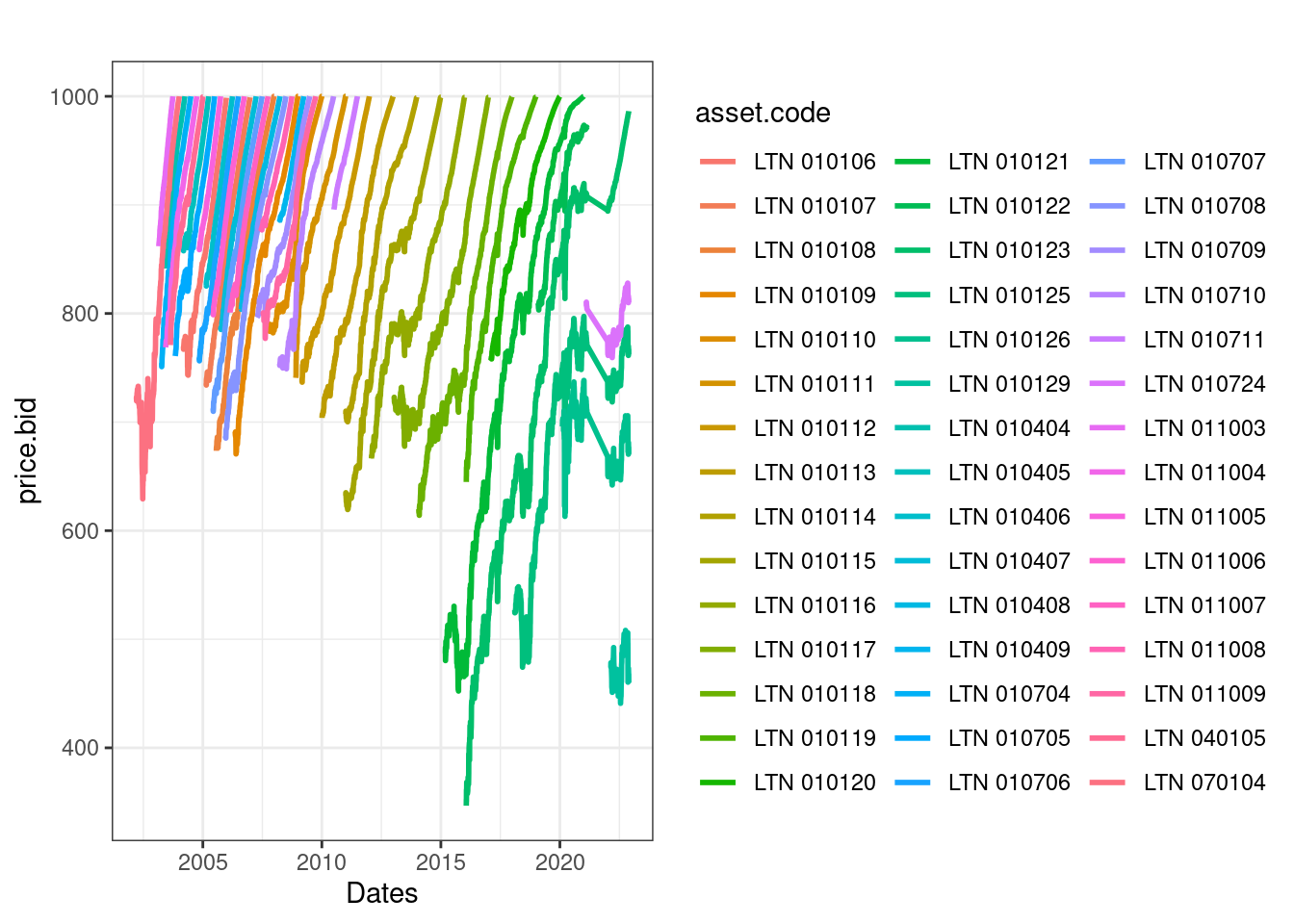
Como esperado de um título de dívida pré-fixado, os preços possuem uma tendência positiva ao longo do tempo, chegando ao valor esperado de 1000 R$ no vencimento em 2021-01-01. Podemos também visualizar as mudanças do yield do título:
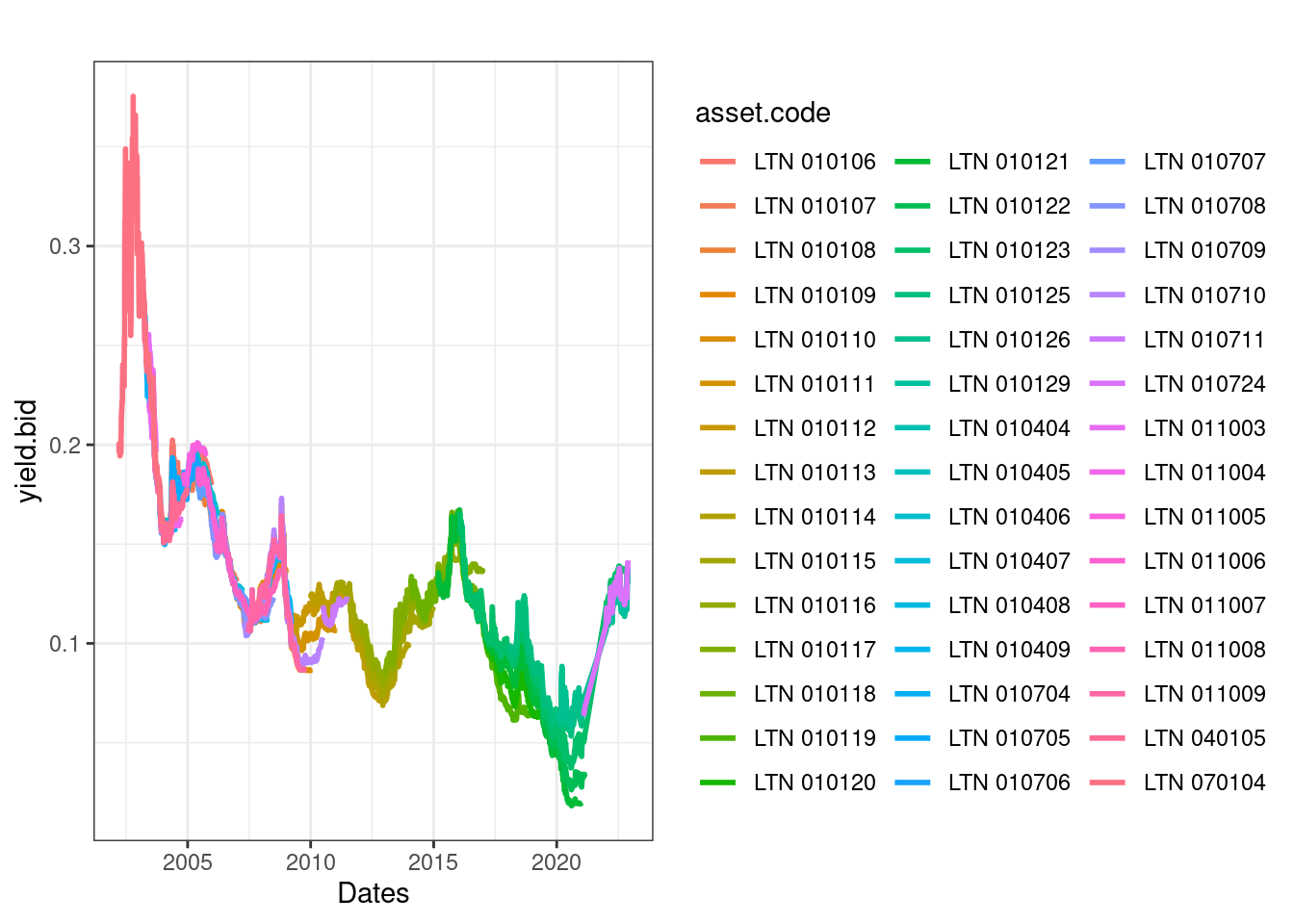
Os retornos do título tiveram forte queda ao longo dos anos. Este resultado é esperado pois o juros do mercado – taxa SELIC – caiu bastante nos últimos cinco anos.
As funções do GetTDData também funcionam com vários argumentos como asset.codes e maturity. Suponhamos que desejamos visualizar todos os preços de todos os prazos disponíveis para títulos do tipo LTN a partir de 2010. Tudo o que precisamos fazer é adicionar o valor NULL ao argumento maturity e filtrar as datas:
library(GetTDData)
asset_codes <- 'LTN' # Name of asset
maturity <- NULL # = NULL, downloads all maturities
# download data
my_flag <- download.TD.data(asset.codes = asset_codes,
do.clean.up = F)
# reads data
df_TD <- read.TD.files()
# remove data prior to 2010
df_TD <- dplyr::filter(df_TD,
ref.date >= as.Date('2010-01-01'))Após a importação das informações, plotamos os preços dos diferentes ativos:
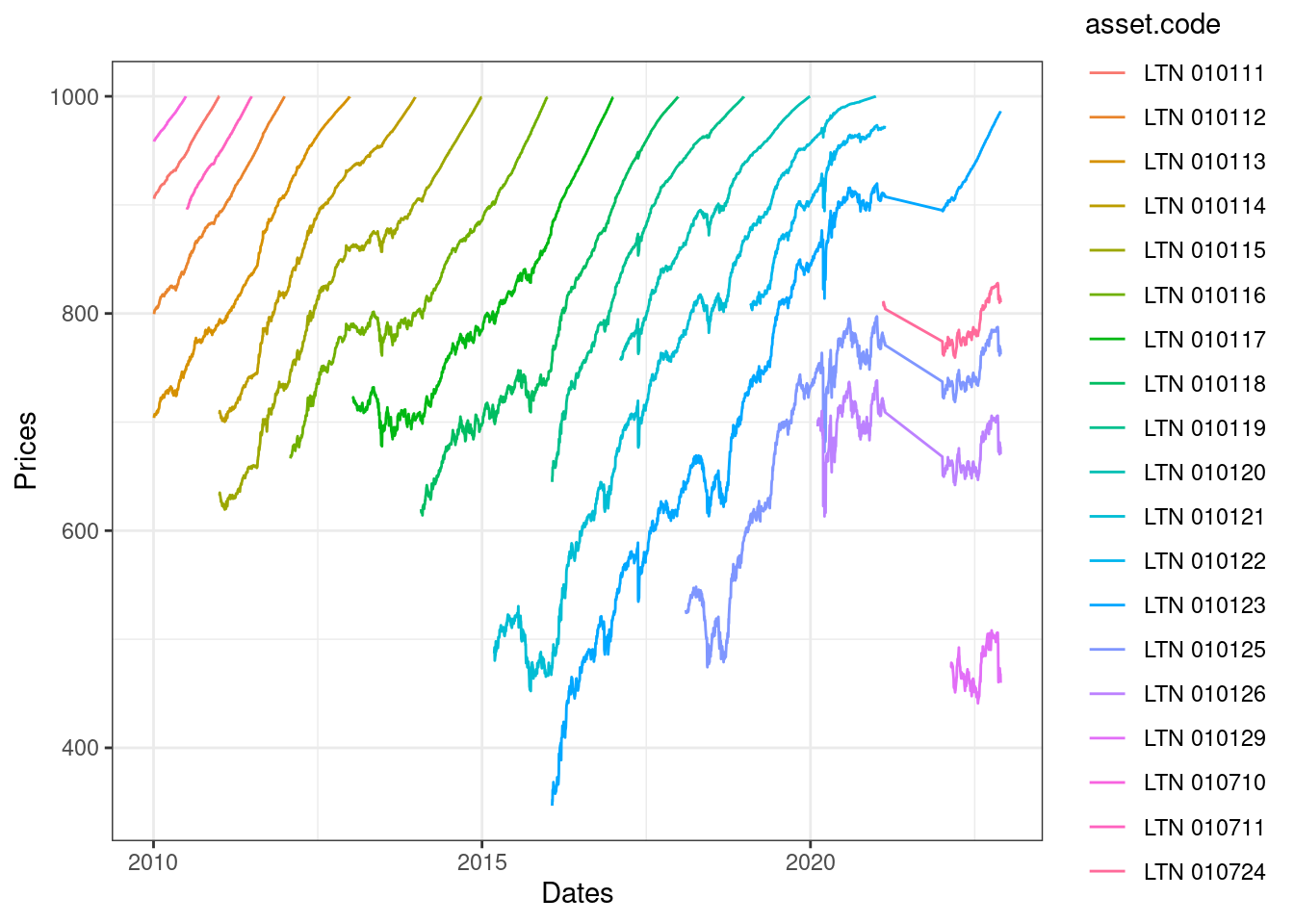
Note como todos contratos do tipo LTN terminam com valor R$ 1.000 em sua data de expiração e possuem uma dinâmica linear de crescimento de preço ao longo do tempo.
Outra funcionalidade do pacote GetTDData é o acesso a curva de juros atual do sistema financeiro brasileiro diretamente do site da Anbima. Para isso, basta utilizar a função get.yield.curve:
library(GetTDData)
# get yield curve
df_yield <- get.yield.curve()
# check result
dplyr::glimpse(df_yield)R> Rows: 114
R> Columns: 5
R> $ n.biz.days <dbl> 126, 252, 378, 504, 630, 756, 882, 10…
R> $ type <chr> "real_return", "real_return", "real_r…
R> $ value <dbl> 6.1355, 6.6490, 6.7057, 6.6214, 6.512…
R> $ ref.date <date> 2023-05-24, 2023-11-23, 2024-05-27, …
R> $ current.date <date> 2022-11-22, 2022-11-22, 2022-11-22, …Os dados incluem a curva de juros nominal, juros real e da inflação. Para melhor visualizar as informações, vamos plotá-las em um gráfico:
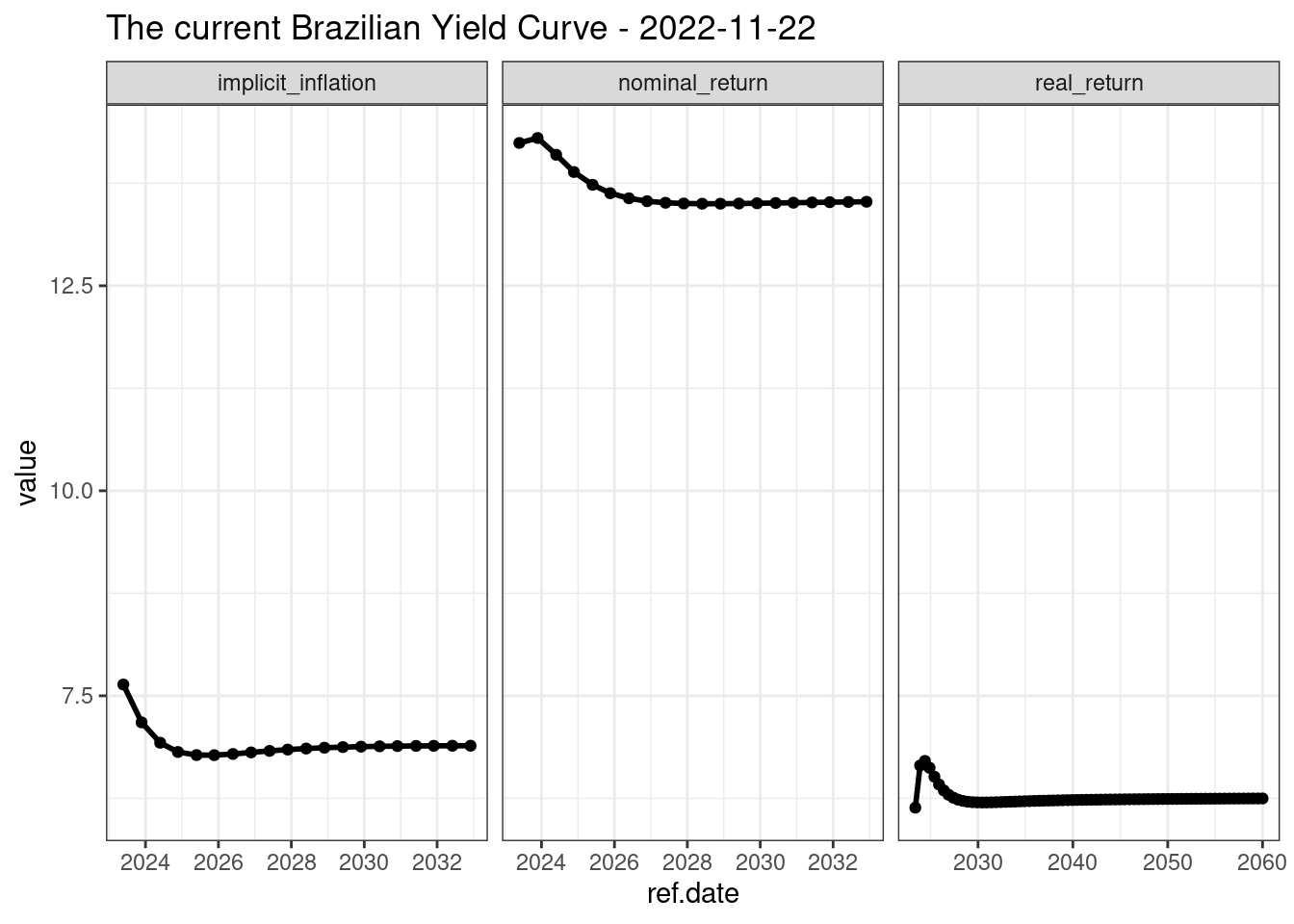
A curva de juros é uma ferramente utilizada no mercado financeiro com o propósito de representar graficamente a expectatica do mercado sobre juros futuro. Baseada nos preços dos títulos públicos, calcula-se e extrapola-se o juros implícito para cada período futuro. Uma curva ascendente, o formato esperado, indica que é mais caro (maior o juro) tomar dinheiro emprestado no longo prazo.
5.4 Pacote GetBCBData
O Banco Central Brasileiro (BCB) disponibiliza em seu Sistema de Séries Temporais (SGS) uma vasta quantidade de tabelas relativas a economia do Brasil. Mais importante, estas tabelas são atualizadas constantemente e o acesso é gratuito e sem necessidade de registro.
Como um exemplo, vamos usar o pacote para estudar a inadimplência de crédito no sistema financeiro Brasileiro. O primeiro passo no uso de GetBCBData é procurar o símbolo da série de interesse. Acessando o sistema de séries temporais do BCB, vemos que o código identificador para o percentual total de inandimplência no Brasil é 21082.
No código, basta indicar a série de interesse e o período de tempo desejado:
library(GetBCBData)
library(dplyr)
# set ids and dates
id_series <- c(perc_default = 21082)
first_date = '2010-01-01'
# get series from bcb
df_cred <- gbcbd_get_series(id = id_series,
first.date = first_date,
last.date = Sys.Date(),
use.memoise = FALSE)R>
R> Fetching perc_default [21082] from BCB-SGS from Online API
R> Found 139 observations
# check it
glimpse(df_cred)R> Rows: 139
R> Columns: 4
R> $ ref.date <date> 2011-03-01, 2011-04-01, 2011-05-01, 2…
R> $ value <dbl> 3.17, 3.24, 3.37, 3.32, 3.42, 3.45, 3.…
R> $ id.num <dbl> 21082, 21082, 21082, 21082, 21082, 210…
R> $ series.name <chr> "perc_default", "perc_default", "perc_…Note que indicamos o nome da coluna na própria definição da entrada id. Assim, coluna series.name toma o nome de perc.default. Esta configuração é importante pois irá diferenciar os dados no caso da importação de diversas séries diferentes. O gráfico apresentado a seguir mostra o valor da série no tempo:
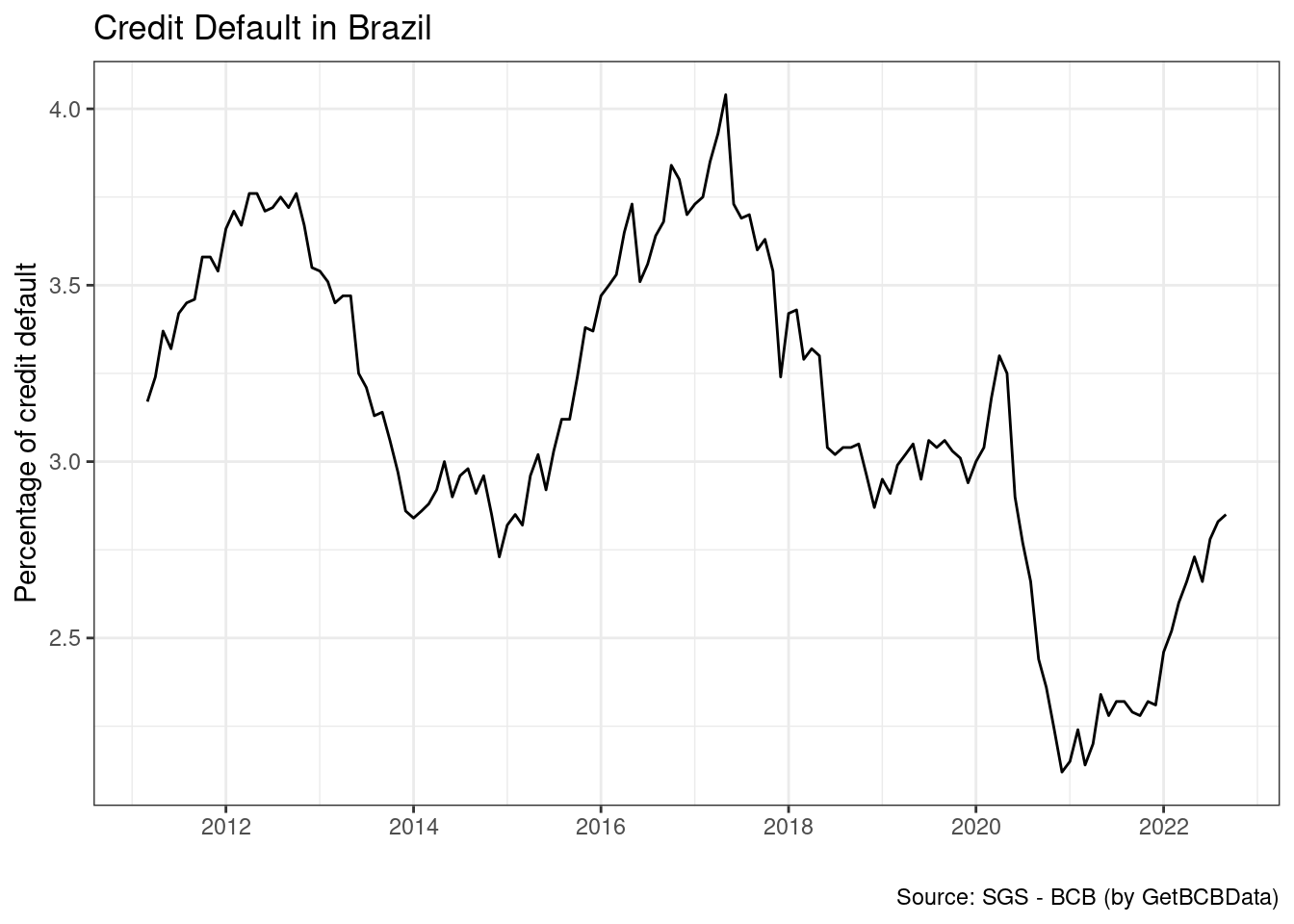
Como podemos ver, a percentagem de inadimplência aumentou a partir de 2015. Para ter uma idéia mais clara do problema, vamos incluir no gráfico a percentagem para pessoa física e pessoa jurídica. Olhando novamente o sistema do BCB, vemos que o símbolos de interesse são 21083 e 21084, respectivamente. O próximo código baixa os dados das duas séries.
# set ids
id.series <- c(credit_default_people = 21083,
credit_default_companies = 21084)
first.date = '2010-01-01'
# get series from bcb
df_cred <- gbcbd_get_series(id = id.series,
first.date = first.date,
last.date = Sys.Date(),
use.memoise = FALSE)R>
R> Fetching credit_default_people [21083] from BCB-SGS from Online API
R> Found 139 observations
R> Fetching credit_default_companies [21084] from BCB-SGS from Online API
R> Found 139 observations
# check output
glimpse(df_cred)R> Rows: 278
R> Columns: 4
R> $ ref.date <date> 2011-03-01, 2011-04-01, 2011-05-01, 2…
R> $ value <dbl> 1.96, 2.04, 2.15, 2.09, 2.18, 2.15, 2.…
R> $ id.num <dbl> 21083, 21083, 21083, 21083, 21083, 210…
R> $ series.name <chr> "credit_default_people", "credit_defau…A diferença na saída do código anterior é que agora temos duas séries temporais empilhadas no mesmo dataframe. Partimos então para a visualização das séries
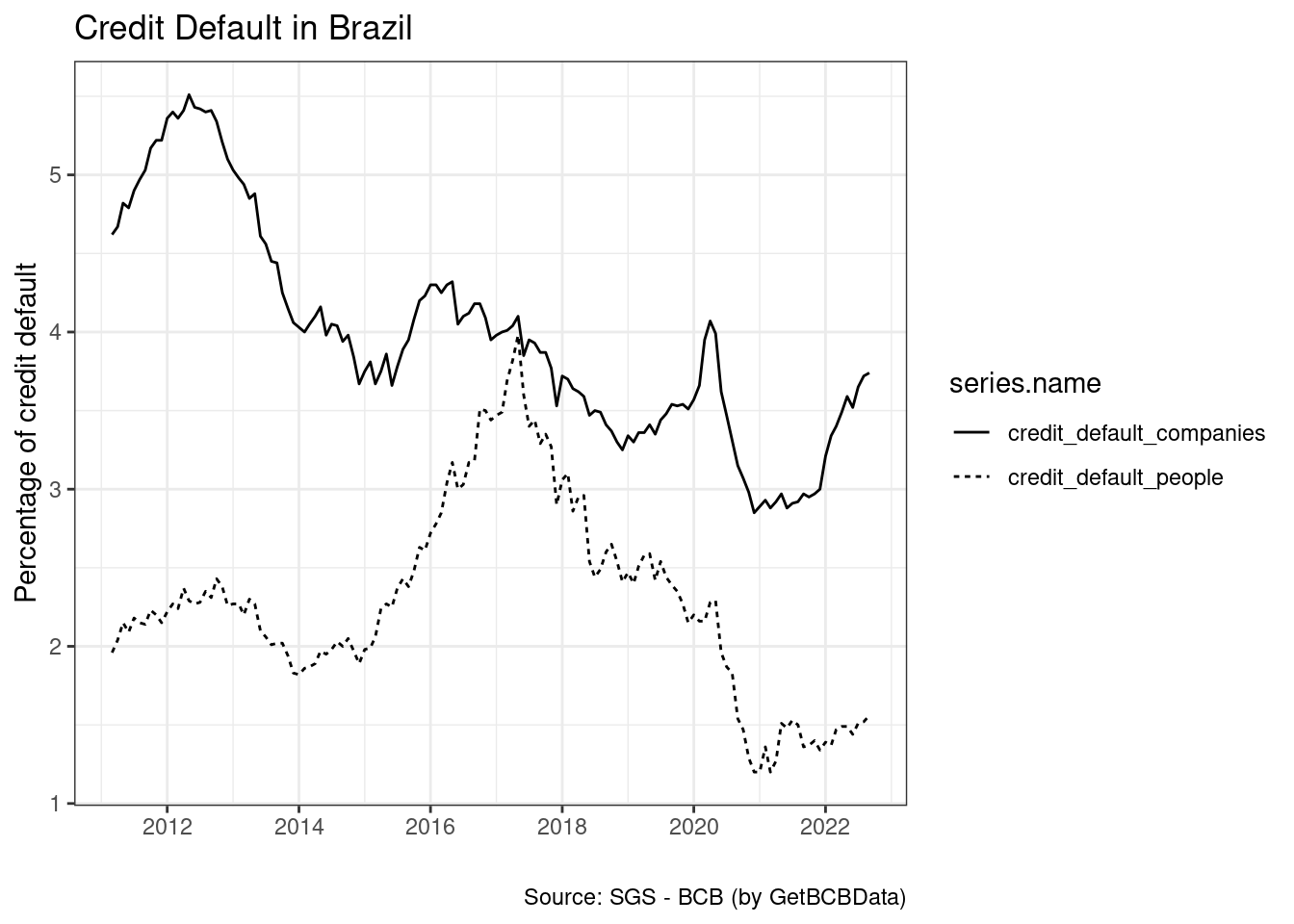
Como podemos ver, a inadimplência de crédito para pessoa física aumentou muito mais do que a para pessoa jurídica (empresas) nos últimos anos. Poderiámos, facilmente, integrar o código anterior para uma análise mais completa dos dados em algum problema de pesquisa.
O sistema BCB-SGS é local obrigatório para qualquer economista sério. A quantidade e variedade de dados é imensa. Podes usar os dados do sistema para automatizar qualquer tipo de relatório econômico.
5.5 Pacote GetDFPData2
Pacote GetDFPData2 (M. Perlin and Kirch 2022a) é uma evolução do pacote GetDFPData (M. Perlin 2021) e fornece uma interface aberta para todas as demonstrações financeiras distribuídas pela B3 e pela CVM nos sistemas DFP (dados anuais) e ITR (dados trimestrais). Ele não só faz o download dos dados, mas também ajusta à inflação e torna as tabelas prontas para pesquisa dentro de um formato tabular. Os diferenciais do pacote em relação a outros distribuidores de dados comerciais são: livre acesso, facilidade para baixar dados em larga escala e a variedade de dados disponíveis.
Uma versão web de GetDFPData2 foi desenvolvida e
publicada na internet como um aplicativo shiny em http://www.msperlin.com/shiny/GetDFPData/.
Esse fornece uma interface gráfica direta e simples para as principais
funcionalidade do pacote. Usuários podem selecionar as empresas
disponíveis, o intervalo de datas e baixar os dados como uma planilha do
Excel ou um arquivo compactado com vários arquivos csv.
Saiba também que dados históricos completos e atualizados a partir de 2010 do DFP e ITR estão disponibilizados na seção Data do meu site pessoal.
O ponto de partida no uso de GetDFPData2 é baixar informações atuais sobre empresas disponíveis. O acesso a tabela é possível com a função get_info_companies:
library(GetDFPData2)
# get info for companies in B3
df_info <- get_info_companies()R> Fetching info on B3 companiesR> Dowloading file from CVMR> File not found, downloading it..R> SuccessR> Reading file from CVMR> Saving cache dataR> Got 2559 lines for 2425 companies [Actives = 701 Inactives = 1736]
# check it
names(df_info)R> [1] "CNPJ" "DENOM_SOCIAL"
R> [3] "DENOM_COMERC" "DT_REG"
R> [5] "DT_CONST" "DT_CANCEL"
R> [7] "MOTIVO_CANCEL" "SIT_REG"
R> [9] "DT_INI_SIT" "CD_CVM"
R> [11] "SETOR_ATIV" "TP_MERC"
R> [13] "CATEG_REG" "DT_INI_CATEG"
R> [15] "SIT_EMISSOR" "DT_INI_SIT_EMISSOR"
R> [17] "CONTROLE_ACIONARIO" "TP_ENDER"
R> [19] "LOGRADOURO" "COMPL"
R> [21] "BAIRRO" "MUN"
R> [23] "UF" "PAIS"
R> [25] "CEP" "DDD_TEL"
R> [27] "TEL" "DDD_FAX"
R> [29] "FAX" "EMAIL"
R> [31] "TP_RESP" "RESP"
R> [33] "DT_INI_RESP" "LOGRADOURO_RESP"
R> [35] "COMPL_RESP" "BAIRRO_RESP"
R> [37] "MUN_RESP" "UF_RESP"
R> [39] "PAIS_RESP" "CEP_RESP"
R> [41] "DDD_TEL_RESP" "TEL_RESP"
R> [43] "DDD_FAX_RESP" "FAX_RESP"
R> [45] "EMAIL_RESP" "CNPJ_AUDITOR"
R> [47] "AUDITOR"Essa tabela disponibiliza os identificadores numéricos das empresas, setores de atividades, atual segmento de governança, tickers negociados na bolsa e situação atual (ativa ou não). O número atual de empresas ativas e inativas, a partir de 2022-11-23, está disponível na coluna SIT_REG. Observa-se 786 empresas ativas e 1771 canceladas. Essa é uma excelente fonte de informação para um estudo exploratório. Pode-se facilmente filtrar empresas para datas, setores, tickers ou segmentos de governança corporativa.
Toda empresa no banco de dados é identificada pelo seu número único da CVM. Função search_company permite que o usuário procure o identificador de uma empresa através de seu nome. Dado um texto de entrada – o nome da empresa –, a função procurará uma correspondência parcial com os nomes de todas as empresas disponíveis no banco de dados. Em seu uso, caracteres latinos e maiúsculas e minúsculas são ignorados. Vamos encontrar o nome oficial nome da Grendene, uma das maiores empresas do Brasil. Para isso, basta usar o comando search_company('grendene').
df_search <- search_company('grendene')
print(df_search)R> # A tibble: 1 × 47
R> CNPJ DENOM…¹ DENOM…² DT_REG DT_CONST DT_CANCEL
R> <chr> <chr> <chr> <date> <date> <date>
R> 1 89.850.3… GRENDE… GRENDE… 2004-10-26 1971-02-25 NA
R> # … with 41 more variables: MOTIVO_CANCEL <chr>,
R> # SIT_REG <chr>, DT_INI_SIT <date>, CD_CVM <dbl>,
R> # SETOR_ATIV <chr>, TP_MERC <chr>, CATEG_REG <chr>,
R> # DT_INI_CATEG <date>, SIT_EMISSOR <chr>,
R> # DT_INI_SIT_EMISSOR <date>, CONTROLE_ACIONARIO <chr>,
R> # TP_ENDER <chr>, LOGRADOURO <chr>, COMPL <chr>,
R> # BAIRRO <chr>, MUN <chr>, UF <chr>, PAIS <chr>, …Vemos que existe um registro para a Grendene: “GRENDENE SA”, com código identificador equivalente a 19615.
Com o identificador da empresa disponível, usamos a função principal do pacote, get_dfp_data, para baixar os dados. Definimos o nome oficial da empresa como entrada companies_cvm_codes e o período de tempo como entradas first_year e last_year.
library(GetDFPData2)
library(dplyr)
# set options
id_companies <- 19615
first_year <- 2017
last_year <- 2018
# download data
l_dfp <- get_dfp_data(companies_cvm_codes = id_companies,
type_docs = '*', # get all docs
type_format = 'con', # consolidated
first_year = first_year,
last_year = last_year)As mensagens de GetDFPData2::get_dfp_data relatam os estágios do processo, desde a aquisição de dados da tabela de referência ao download e leitura dos arquivos da B3. Observe que os arquivos de três sistemas são acessados: DFP (Demostrativos Financeiros Padronizados), FRE (Formulário de Referência) e FCA (Formulário Cadastral). Observe também o uso de um sistema de cache, o qual acelera significativamente o uso do software ao salvar localmente as informações importadas.
Explicando as demais entradas da função GetDFPData2::get_dfp_data:
- companies_cvm_codes
-
Código numérico das empresas (encontrado via
GetDFPData2::search_company('ambev')) - type_docs
- Símbolo do tipo de documento financeiro a ser retornado. Definições: ’*’ = retorna todos documentos, ‘BPA’ = Ativo, ‘BPP’ = passivo, ‘DRE’ = demonstrativo de resultados do exercício, ‘DFC_MD’ = fluxo de caixa pelo metodo direto, ‘DFC_MI’ = fluxo de caixa pelo metodo indireto, ‘DMPL’ = mutacoes do patrimonio liquido, ‘DVA’ = demonstrativo de valor agregado.
- type_format
- Tipo de formato dos documentos: consolidado (‘con’) ou individual (‘ind’). Como regra, dê preferência ao tipo consolidado, o qual incluirá dados completos de subsidiárias.
- first_year
- Primeiro ano para os dados
- last_year
- Último ano para os dados
O objeto resultante de get_dfp_data é uma lista com diversas tabelas. Vamos dar uma olhada no conteúdo de l_dfp ao buscar os nomes dos itens da lista, limitando o número de caracteres:
R> [1] "DF Consolidado - Balanço Patrimonial Ati"
R> [2] "DF Consolidado - Balanço Patrimonial Pas"
R> [3] "DF Consolidado - Demonstração das Mutaçõ"
R> [4] "DF Consolidado - Demonstração de Valor A"
R> [5] "DF Consolidado - Demonstração do Fluxo d"
R> [6] "DF Consolidado - Demonstração do Resulta"Como podemos ver, os dados retornados são vastos. Cada item da lista em l_dfp é um tabela indexada ao tempo. A explicação de cada coluna não cabe aqui mas, para fins de exemplo, vamos dar uma olhada no balanço patrimonial da empresa, disponível em l_dfp$"DF Consolidado - Balanço Patrimonial Ativo":
# save assets in df
fr_assets <- l_dfp$`DF Consolidado - Balanço Patrimonial Ativo`
# check it
dplyr::glimpse(fr_assets)R> Rows: 122
R> Columns: 16
R> $ CNPJ_CIA <chr> "89.850.341/0001-60", "89.850.341/000…
R> $ CD_CVM <dbl> 19615, 19615, 19615, 19615, 19615, 19…
R> $ DT_REFER <date> 2017-12-31, 2017-12-31, 2017-12-31, …
R> $ DT_INI_EXERC <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, …
R> $ DT_FIM_EXERC <date> 2017-12-31, 2017-12-31, 2017-12-31, …
R> $ DENOM_CIA <chr> "GRENDENE S.A.", "GRENDENE S.A.", "GR…
R> $ VERSAO <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
R> $ GRUPO_DFP <chr> "DF Consolidado - Balanço Patrimonial…
R> $ MOEDA <chr> "REAL", "REAL", "REAL", "REAL", "REAL…
R> $ ESCALA_MOEDA <chr> "MIL", "MIL", "MIL", "MIL", "MIL", "M…
R> $ ORDEM_EXERC <chr> "ÚLTIMO", "ÚLTIMO", "ÚLTIMO", "ÚLTIMO…
R> $ CD_CONTA <chr> "1", "1.01", "1.01.01", "1.01.02", "1…
R> $ DS_CONTA <chr> "Ativo Total", "Ativo Circulante", "C…
R> $ VL_CONTA <dbl> 3576008, 2846997, 30119, 1537477, 836…
R> $ COLUNA_DF <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
R> $ source_file <chr> "dfp_cia_aberta_BPA_con_2017.csv", "d…A exportação dos dados para o Excel também é fácil, basta usar função GetDFPData2::export_xlsx:
temp_xlsx <- tempfile(fileext = '.xlsx')
export_xlsx(l_dfp = l_dfp, f_xlsx = temp_xlsx)O arquivo Excel resultante conterá cada tabela de l_dpf em uma aba diferente da planilha, com uma truncagem nos nomes. Podemos checar o resultado com função readxl::excel_sheets:
readxl::excel_sheets(temp_xlsx)R> [1] "DF Consolidado - Balanço Pat"
R> [2] "DF Consolidado - Balanço Pat_1"
R> [3] "DF Consolidado - Demonstraçã"
R> [4] "DF Consolidado - Demonstraçã_1"
R> [5] "DF Consolidado - Demonstraçã_2"
R> [6] "DF Consolidado - Demonstraçã_3"
5.6 Pacote GetFREData
O pacote GetFREData importa dados do sistema FRE – Formulário de Referência – da bolsa Brasileira, incluindo eventos e informações corporativas tal como composição do conselho e diretoria, remuneração dos conselhos, entre outras.
A estrutura de uso e a saída das funções de GetFREData são muito semelhante as do pacote GetDFPData2. Veja a seguir um exemplo de uso.
library(GetFREData)
# set options
id_companies <- 23264
first_year <- 2017
last_year <- 2018
# download data
l_fre <- get_fre_data(companies_cvm_codes = id_companies,
first_year = first_year,
last_year = last_year)Note que o tempo de execução de get_fre_data é significativo. Isto deve-se ao download e leitura dos arquivos do sistema FRE direto da bolsa. Cada tabela do FRE é importada na lista de saída:
names(l_fre)R> [1] "df_stockholders"
R> [2] "df_capital"
R> [3] "df_stock_values"
R> [4] "df_mkt_value"
R> [5] "df_increase_capital"
R> [6] "df_capital_reduction"
R> [7] "df_compensation"
R> [8] "df_compensation_summary"
R> [9] "df_transactions_related"
R> [10] "df_other_events"
R> [11] "df_stock_repurchases"
R> [12] "df_debt_composition"
R> [13] "df_board_composition"
R> [14] "df_committee_composition"
R> [15] "df_family_relations"
R> [16] "df_family_related_companies"
R> [17] "df_auditing"
R> [18] "df_responsible_docs"
R> [19] "df_stocks_details"
R> [20] "df_dividends_details"
R> [21] "df_intangible_details"Por exemplo, vamos verificar conteúdo da tabela df_board_composition, a qual contém informações sobre os componentes dos conselhos das empresas:
glimpse(l_fre$df_board_composition)R> Rows: 59
R> Columns: 22
R> $ CNPJ_CIA <chr> "07.526.557/0001-00", "07…
R> $ DENOM_CIA <chr> "AMBEV S.A.", "AMBEV S.A.…
R> $ DT_REFER <date> 2017-01-01, 2017-01-01, …
R> $ CD_CVM <dbl> 23264, 23264, 23264, 2326…
R> $ ID_DOC <dbl> 74969, 74969, 74969, 7496…
R> $ VERSAO <dbl> 10, 10, 10, 10, 10, 10, 1…
R> $ person.name <chr> "Paula Nogueira Lindenber…
R> $ person.cpf <dbl> 26712117836, 25661215835,…
R> $ person.profession <chr> "Administradora", "Engenh…
R> $ person.cv <chr> "Nos últimos 5 anos, ocup…
R> $ person.dob <date> NA, NA, NA, NA, NA, NA, …
R> $ code.type.board <chr> "1", "1", "1", "1", "1", …
R> $ desc.type.board <chr> "Director", "Director", "…
R> $ desc.type.board2 <chr> "Diretora de Marketing", …
R> $ code.type.job <chr> "19", "19", "19", "19", "…
R> $ desc.job <chr> "Não aplicável, uma vez q…
R> $ date.election <date> 2016-05-11, 2016-05-11, …
R> $ date.effective <date> 2016-05-11, 2016-05-11, …
R> $ mandate.duration <chr> "11/05/2019", "30/06/2018…
R> $ ellected.by.controller <lgl> TRUE, TRUE, TRUE, TRUE, T…
R> $ qtd.consecutive.mandates <dbl> 2, 2, 2, 2, 2, 1, 2, 1, 1…
R> $ percentage.participation <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0…Como podemos ver, para um pesquisador de finanças corporativas, o sistema FRE oferece uma série de informações interessantes. Discutir o conteúdo de cada tabela, porém, vai muito além do propósito dessa seção. Aos interessados, mais detalhes sobre as tabelas do FRE estão disponíveis em M. Perlin, Kirch, and Vancin (2018).
Note que a importação dos dados do FRE inclui uma versão dos
arquivos. Toda vez que uma empresa modifica as informações oficiais no
sistema da B3, uma nova versão do FRE é criada. Devido a isso, é
bastante comum que os dados de um ano para uma empresa possua diferentes
versões. Para resolver este problema, o código do
GetFREData, por default, importa a versão mais
antiga para cada ano. Caso o usuário queira mudar, basta utilizar a
entrada fre_to_read.
5.7 Outros Pacotes
Nas seções anteriores destacamos os principais pacotes gratuitos para aquisição de dados financeiros e econômicos no Brasil. Muitos desses foram escritos pelo próprio autor do livro e representam uma pequena parcela da totalidade. Não seria justo ignorar o trabalho de outros autores. Assim, reporto abaixo uma seleção de pacotes que vale a pena conhecer:
5.7.1 Pacotes de Acesso Gratuito
-
BETS(Ferreira, Speranza, and Costa 2018) - Pacote construído e mantido pela equipe da FGV. Permite o acesso aos dados do BCB (Banco Central do Brasil) e IBGE (Instituto Brasileiro de Geografia e Estatística). Também inclui ferramentas para a administração, análise e manipulação dos dados em relatórios técnicos.
-
simfinapi(Gomolka 2021) - Pacote para acesso ao projeto simfin, incluindo dados financeiros de diversas empresas internacionais. O acesso livre é restrito a um número de chamadas diárias.
5.7.2 Pacotes Comerciais
-
Rblpapi(Armstrong, Eddelbuettel, and Laing 2022) - Permite acesso aos dados da Bloomberg, sendo necessário uma conta comercial.
-
IBrokers(Ryan and Ulrich 2022a) - API para o acesso aos dados da Interactive Brokers. Também é necessário uma conta comercial.
No CRAN você encontrará muitos outros. A interface para fontes de dados comerciais também é possível. Várias empresas fornecem APIs para facilitar o envio de dados aos seus clientes. Se a empresa de fornecimento de dados que você usa no trabalho não for apresentada aqui, a lista de pacotes CRAN pode ajudá-lo a encontrar uma alternativa viável.
5.8 Acessando Dados de Páginas na Internet (Webscraping)
Os pacotes destacados anteriormente são muito úteis pois facilitam a importação de dados específicos diretamente da internet. Em muitos casos, porém, os dados de interesse não estão disponíveis via API formal, mas sim em uma página na internet - geralmente no formato de uma tabela. O processo de extrair informações de páginas da internet chama-se webscraping (raspagem de dados). Dependendo da estrutura e da tecnologia da página da web acessada, importar essas informações diretamente para o R pode ser um procedimento trivial – mas também pode se tornar um processo extremamente trabalhoso. Como um exemplo, a seguir vamos raspar dados do Wikipedia sobre a composição do índice SP500.
5.8.1 Raspando Dados do Wikipedia
Em seu site, a Wikipedia oferece uma seção21 com os componentes do Índice SP500. Essas informações são apresentadas em um formato tabular, Figura 5.1.
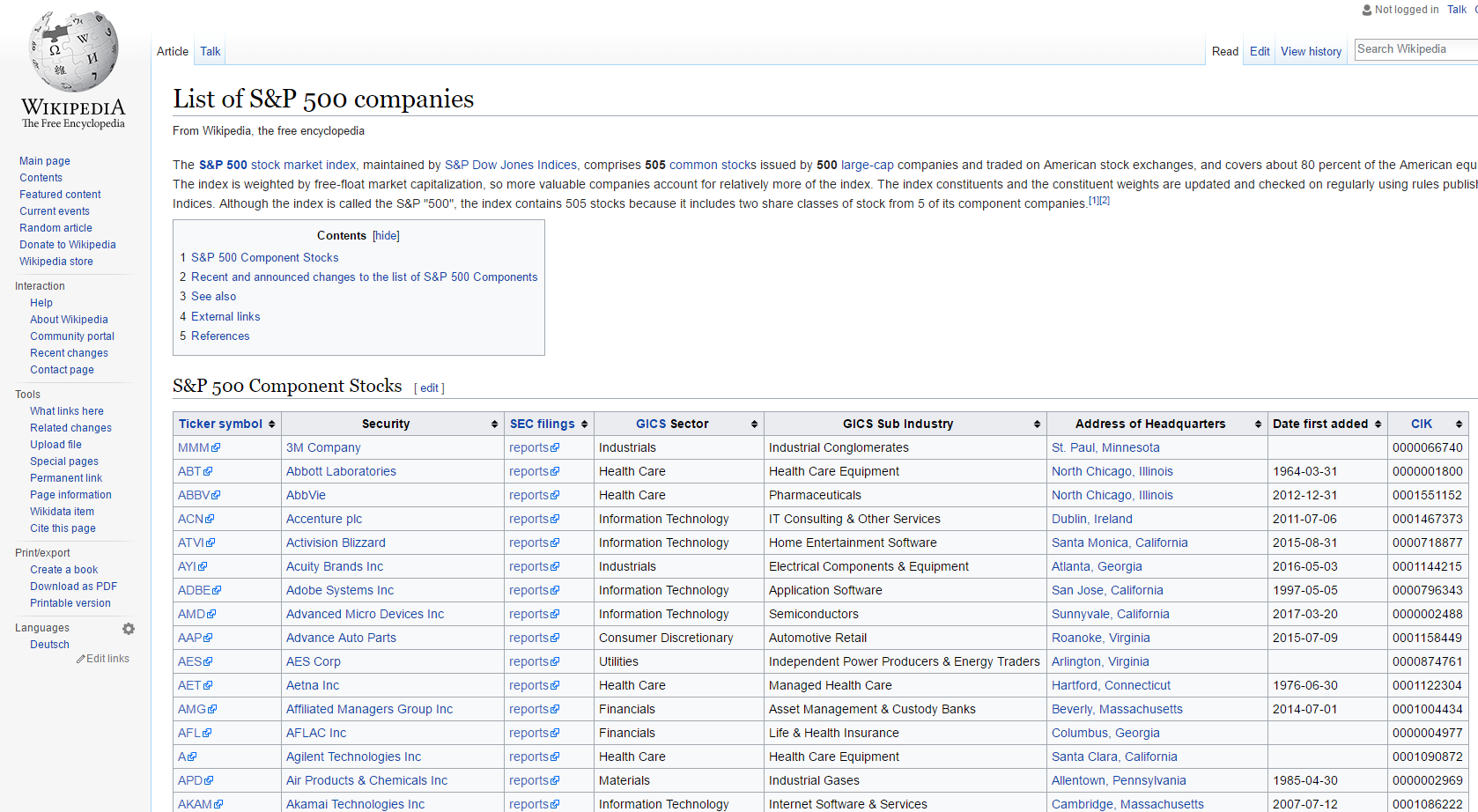
Figura 5.1: Imagem da página do Wikipedia
As informações desta página são constantemente atualizadas, e podemos utilizá-las para importar informações sobre as ações pertencentes ao índice SP500. Antes de nos aprofundarmos no código R, precisamos entender como uma página da web funciona. Resumidamente, uma página da web nada mais é do que uma árvore com nódulos, representada por um código HTML (Hypertext Markup Language) extenso interpretado pelo seu navegador. Um valor numérico ou texto apresentado no site geralmente pode ser encontrado dentro do próprio código. Este código tem uma estrutura particular em forma de árvore com ramificações, classes, nomes e identificadores. Além disso, cada elemento de uma página da web possui um endereço, denominado xpath. Nos navegadores Chrome e Firefox, você pode ver o código HTML de uma página da web usando o mouse. Para isto, basta clicar com o botão direito em qualquer parte da página e selecionar View Page Source (ou “Ver Código Fonte”).
A primeira etapa do processo de raspagem de dados é descobrir a localização das informações de que você precisa. No navegador Chrome, você pode fazer isso clicando com o botão direito no local específico do número/texto no site e selecionando inspect. Isso abrirá uma janela extra no navegador a direita. Depois de fazer isso, clique com o botão direito na seleção e escolha copy e copy xpath. Na Figura 5.2, vemos um espelho do que você deve estar vendo em seu navegador.
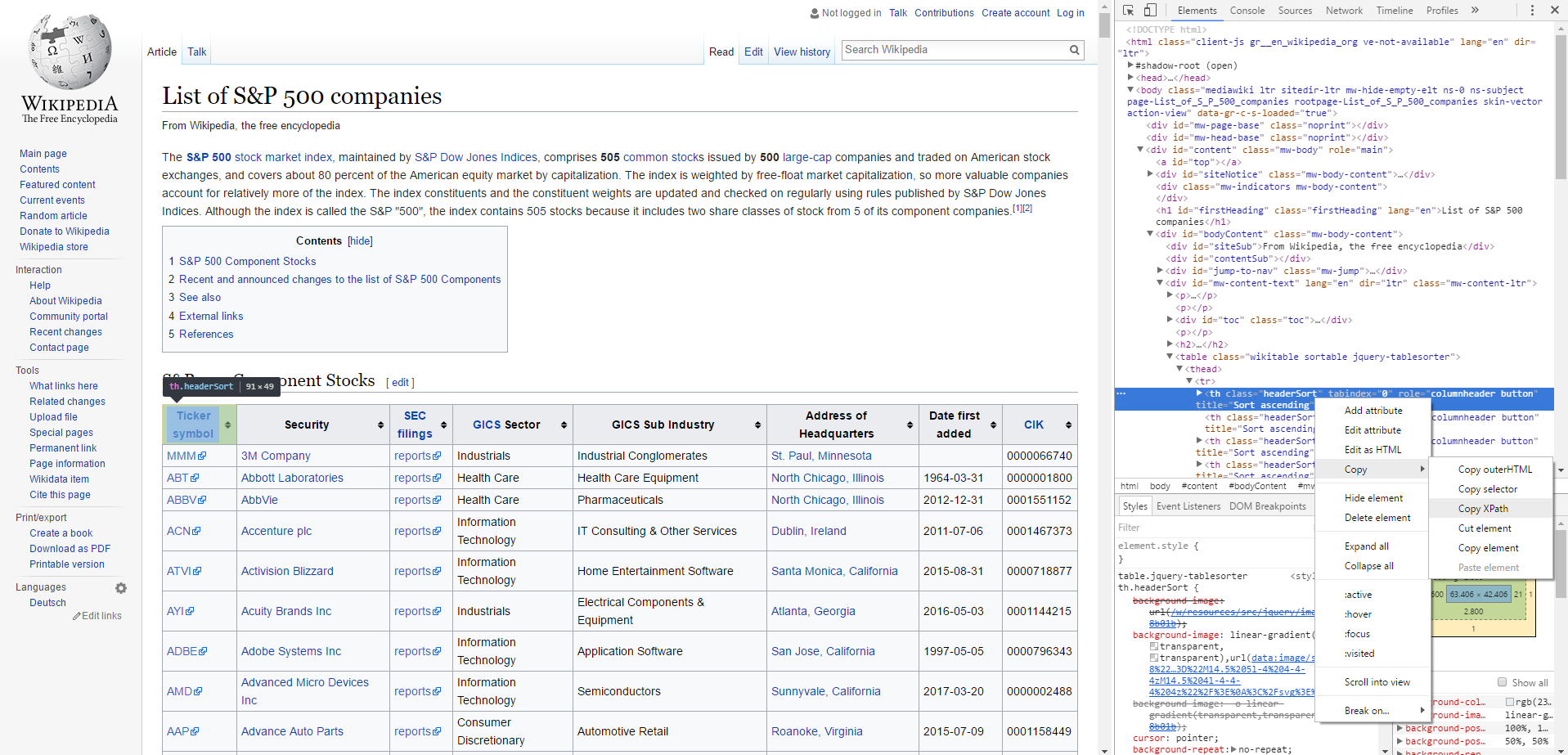
Figura 5.2: Encontrando o xpath da tabela
Aqui, o texto copiado é:
'//*[@id="mw-content-text"]/table[1]/thead/tr/th[2]'Este é o endereço do cabeçalho da tabela. Para todo o conteúdo da tabela, incluindo cabeçalho, linhas e colunas, precisamos definir um nível superior da árvore. Isso é equivalente ao endereço //*[@id =" mw-content-text"]/table[1].
Agora que temos a localização do que queremos, vamos carregar o pacote rvest (Wickham 2022a) e usar as funções read_html, html_nodes ehtml_table para importar a tabela desejada para o R:
library(rvest)
# set url and xpath
my_url <- 'https://en.wikipedia.org/wiki/List_of_S%26P_500_companies'
my_xpath <- '//*[@id="mw-content-text"]/div/table[1]'
# get nodes from html
out_nodes <- html_nodes(read_html(my_url),
xpath = my_xpath)
# get table from nodes (each element in
# list is a table)
df_SP500_comp <- html_table(out_nodes)
# isolate it
df_SP500_comp <- df_SP500_comp[[1]]
# change column names (remove space)
names(df_SP500_comp) <- make.names(names(df_SP500_comp))
# print it
glimpse(df_SP500_comp)R> Rows: 503
R> Columns: 9
R> $ Symbol <chr> "MMM", "AOS", "ABT", "ABBV",…
R> $ Security <chr> "3M", "A. O. Smith", "Abbott…
R> $ SEC.filings <chr> "reports", "reports", "repor…
R> $ GICS.Sector <chr> "Industrials", "Industrials"…
R> $ GICS.Sub.Industry <chr> "Industrial Conglomerates", …
R> $ Headquarters.Location <chr> "Saint Paul, Minnesota", "Mi…
R> $ Date.first.added <chr> "1976-08-09", "2017-07-26", …
R> $ CIK <int> 66740, 91142, 1800, 1551152,…
R> $ Founded <chr> "1902", "1916", "1888", "201…O objeto df_SP500_comp contém um espelho dos dados do site da Wikipedia. Os nomes das colunas requerem algum trabalho de limpeza, mas o principal está ali. Observe como a saída é semelhante aos dados da função BatchGetSymbols::GetSP500Stocks. A razão é simples, ambas buscaram a informação na mesma origem. A diferença é que função GetSP500Stocks vai um passo além, limpando os dados importados.
5.9 Exercícios
Q.1
Using the yfR package, download daily data for ticker TSLA from Yahoo Finance for the period between 2019-01-01 and 2020-03-02. What is the lowest unadjusted closing price (column price_close) in the analyzed period?
Resposta:
possible_tickers <- c('META', "TSLA", "MMM", "GE")
ticker <- sample(possible_tickers, 1)
first_date <- as.Date('2019-01-01')
last_date <- sample(
seq(first_date+50, Sys.Date()-10, by = '1 day'),
1)
df_prices <- yfR::yf_get(tickers = ticker,
first_date = first_date,
last_date = last_date)
my_sol <- min(df_prices$price_close,
na.rm = TRUE)
Q.2
If you have not already done so, create a profile on the Quandl website22 and download the arabica coffee price data (id = CEPEA/COFFEE_A) in the CEPEA database (Center for Advanced Studies in Applied Economics) between 2010-01-01 and 2019-09-27. What is the maximum price found?
Resposta:
Q.3
Utilize pacote GetBCBData para baixar dados do IPCA mensal entre 2010-01-01 e 2020-12-31. Para os dados importados, qual é a data com o maior valor mensal de inflação?
Resposta:
Q.4
Use function simfinapi::sfa_get_entities to import data about all available companies in Simfin. How many companies do you find?
Resposta:
Q.5
With package simfinapi, download the PnL (profit and loss) statement for FY (final year) data for id = 134979) for year 2019. What is the latest “Net Income” of the company?
Resposta:
Q.6
Using again the yfR package, download data between 2019-01-01 and 2021-05-30 for the following tickers:
- AAPL: Apple Inc
- BAC: Bank of America Corporation
- GE: General Electric Company
- TSLA: Tesla, Inc.
- SNAP: Snap Inc.
Using the adjusted closing price column, what company provided higher return to the stock holder during the analyzed period?
Tip: this is an advanced exercise that will require some coding. To solve it, check out function split to split the dataframe of price data and lapply to map a function to each dataframe.
Resposta:
first_date <- as.Date('2019-01-01')
last_date <- sample(
seq(first_date+50, Sys.Date()-10, by = '1 day'),
1)
my_tickers <- c('AAPL', 'BAC',
'GE', 'TSLA',
'SNAP')
df_prices <- yfR::yf_get(tickers = my_tickers,
first_date = first_date,
last_date = last_date)
split_l <- split(df_prices, df_prices$ticker)
my_fct <- function(df_in) {
price_vec <- df_in$price_adjusted
ticker_in <- df_in$ticker[1]
total_ret <- last(price_vec)/first(price_vec) - 1
return(tibble(ticker = ticker_in,
total_ret = total_ret))
}
df_results <- bind_rows(
lapply(split_l, my_fct)
)
winner <- df_results$ticker[which.max(df_results$total_ret)]
my_sol <- winner
Q.7
Using package GetDFPData2, download the main table with all available companies. What is the number of active companies currently available?
Resposta:
df_info <- GetDFPData2::get_info_companies() |>
dplyr::filter(SIT_REG == "ATIVO")
my_sol <- nrow(df_info)
Q.8
Using package GetDFPData2, download net income data (consolidated) for all companies in the year of 2019. What is the sum of profit/loss (in thousands, code 3.11 in DFP) for all companies?
Resposta:
df_info <- GetDFPData2::get_info_companies() |>
dplyr::filter(SIT_REG == "ATIVO")
year <- sample(2015:(lubridate::year(Sys.Date())-1), 1)
l_dfp <- GetDFPData2::get_dfp_data(first_year = year,
last_year = year)
ni <- l_dfp$`DF Consolidado - Demonstração do Resultado` |>
dplyr::filter(CD_CONTA == "3.11")
my_sol <- sum(ni$VL_CONTA)
Q.9
Using package GetTDData, download all available data for debt contract of type LTN (pré-fixados).
What is the maximum yield (column yield.bid) found for for contract LTN 010118?
Resposta:
my_temp_path <- fs::path_temp('TD')
GetTDData::download.TD.data(asset.codes = "LTN",
dl.folder = my_temp_path)
df_td <- GetTDData::read.TD.files(dl.folder = my_temp_path)
available_assets <- unique(df_td$asset.code)
my_asset <- sample(available_assets, 1)
df_asset <- df_td |>
dplyr::filter(asset.code == my_asset)
my_sol <- max(df_asset$yield.bid)